

AIの研究者がスパーススペクトル学習について話している理由

リンク一覧
概要と1. はじめに
-
関連研究
-
低ランク適応
3.1 LoRAと3.2 LoRAの限界
3.3 ReLoRA*
-
スパース・スペクトル・トレーニング
4.1 予備知識と4.2 ΣによるU、VTの勾配更新
4.3 なぜSVD初期化が重要か
4.4 SSTは活用と探索のバランスを取る
4.5 SSTのメモリ効率の良い実装と4.6 SSTのスパース性
-
実験
5.1 機械翻訳
5.2 自然言語生成
5.3 双曲線グラフニューラルネットワーク
-
結論と考察
-
より広範な影響と参考文献
補足情報
A. スパース・スペクトル・トレーニングのアルゴリズム
B. スパース・スペクトル層の勾配の証明
C. 重みの勾配分解の証明
D. デフォルト勾配に対する強化された勾配の優位性の証明
E. SVD初期化によるゼロ歪みの証明
F. 実験の詳細
G. 特異値プルーニング
H. SSTとGaLoreの評価:メモリ効率への補完的アプローチ
I. アブレーション研究
A スパース・スペクトル・トレーニングのアルゴリズム
B スパース・スペクトル層の勾配の証明
Wの微分を微分の和として表現できます:
\ \ 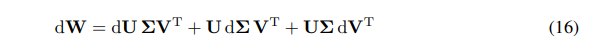
\ \ Wの勾配に対する連鎖律があります:
\ \ 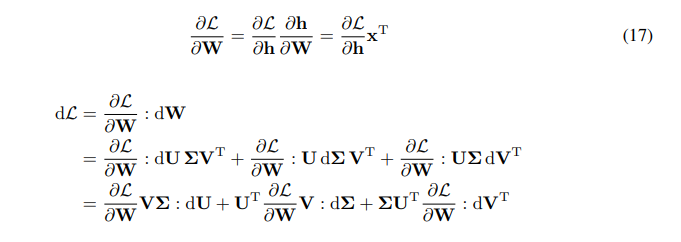
\ \ \ 
\
C 重みの勾配分解の証明
\ 
\
D デフォルト勾配に対する強化された勾配の優位性の証明
\ 
\ \ \ 
\ \ \ 
\ \ 更新の方向のみが重要であるため、更新のスケールは学習率を変更することで調整できます。類似性は、SST更新とフルランク更新の3倍との差のフロベニウスノルムを使用して測定します。
\ \ 
\
E SVD初期化によるゼロ歪みの証明
\ 
F 実験の詳細
F.1 SSTの実装詳細
\ 
\ \ \ 
\
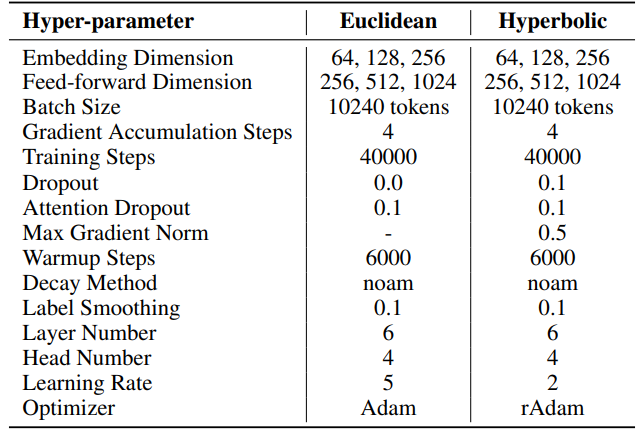
F.2 機械翻訳のハイパーパラメータ
IWSLT'14. ハイパーパラメータは表6に記載されています。HyboNet [12]で使用されたものと同じコードベースとハイパーパラメータを採用しており、これはOpenNMT-py [54]から派生しています。評価には最終モデルのチェックポイントを使用しています。評価プロセスを最適化するために、ビームサイズ2のビーム検索を採用しています。実験は1台のA100 GPUで実施されました。
\ SSTでは、イテレーションごとのステップ数(T3)は200に設定されています。各イテレーションは20ステップの準備フェーズから始まります。ラウンドごとのイテレーション数(T2)はT2 = d/rという式で決定されます。ここでdは埋め込み次元を表し、rはSSTで使用されるランクを示します。
\ \ 
\ \ \ 
\ \ SSTでは、イテレーションごとのステップ数(T3)はMulti30Kでは200、IWSLT'17では400に設定されています。各イテレーションは20ステップの準備フェーズから始まります。ラウンドごとのイテレーション数(T2)はT2 = d/rという式で決定されます。ここでdは埋め込み次元を表し、rはSSTで使用されるランクを示します
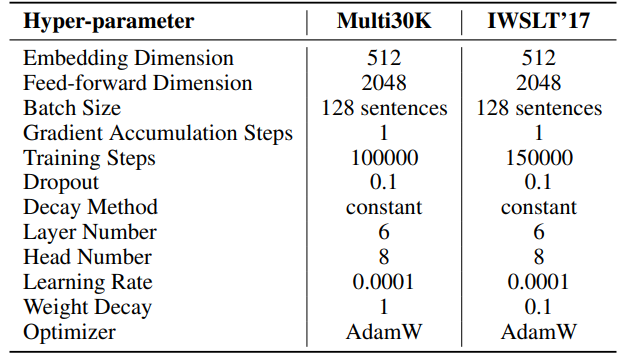
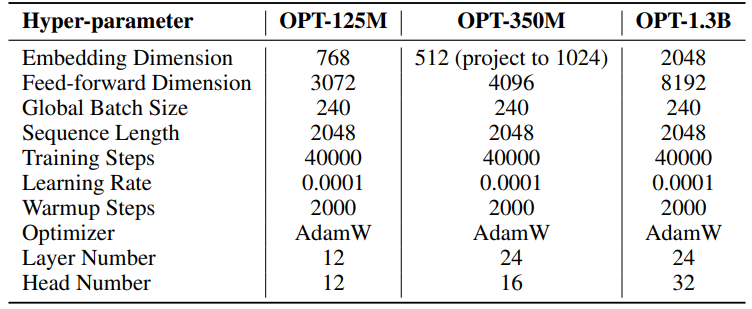
F.3 自然言語生成のハイパーパラメータ
実験のハイパーパラメータは表8に詳細が記載されています。2000ステップの線形ウォームアップの後、減衰なしの安定した学習率を採用しています。低ランクパラメータ(SSTのU、VTとΣ、LoRAとReLoRA*のBとA)に対してのみ、より大きな学習率(0.001)を使用しています。各実験の総トレーニングトークンは19.7Bで、OpenWebTextの約2エポックに相当します。分散トレーニングはLinuxサーバー上の4台のA100 GPUにわたってAccelerate [55]ライブラリを使用して実施されています。
\ SSTでは、イテレーションごとのステップ数(T3)は200に設定されています。各イテレーションは20ステップの準備フェーズから始まります。ラウンドごとのイテレーション数(T2)はT2 = d/rという式で決定されます。ここでdは埋め込み次元を表し、rはSSTで使用されるランクを示します。
\ \ 
\ \ \ 
\
F.4 双曲線グラフニューラルネットワークのハイパーパラメータ
HyboNet [12]をフルランクモデルとして使用し、HyboNetで使用されたものと同じハイパーパラメータを採用しています。実験は1台のA100 GPUで実施されました。
\ SSTでは、イテレーションごとのステップ数(T3)は100に設定されています。各イテレーションは100ステップの準備フェーズから始まります。ラウンドごとのイテレーション数(T2)はT2 = d/rという式で決定されます。ここでdは埋め込み次元を表し、rはSSTで使用されるランクを示します。
\ Coraデータセットでのノード分類タスク中、LoRAとSSTメソッドのドロップアウト率を0.5に設定しました。これはHyboNet構成からの唯一の逸脱です。
\ \ \
:::info 著者:
(1) Jialin Zhao, 複雑ネットワークインテリジェンスセンター(CCNI)、清華大学脳・インテリジェンス研究所(THBI)およびコンピュータサイエンス学部;
(2) Yingtao Zhang, 複雑ネットワークインテリジェンスセンター(CCNI)、清華大学脳・インテリジェンス研究所(THBI)およびコンピュータサイエンス学部;
(3) Xinghang Li, コンピュータサイエンス学部;
(4) Huaping Liu, コンピュータサイエンス学部;
(5) Carlo Vittorio Cannistraci, 複雑ネットワークインテリジェンスセンター(CCNI)、清華大学脳・インテリジェンス研究所(THBI)、コンピュータサイエンス学部、および生物医学工学部 清華大学、北京、中国。
:::
:::info この論文はarxivで入手可能であり、CC by 4.0 Deed(Attribution 4.0 International)ライセンスの下で公開されています。
:::
\


関連コンテンツ

イーサリアム財団、価格が「ラストポンプ」に備える中、1,100万ドル相当のETHを売却

暗号資産規制が加熱、Coinbase CEOがCLARITY法案を支持




