

強健的遮罩引導去背:管理雜訊輸入與物件多樣性
連結目錄
摘要與 1. 引言
-
相關研究
-
MaGGIe
3.1. 高效遮罩引導實例摳圖
3.2. 特徵-遮罩時間一致性
-
實例摳圖資料集
4.1. 影像實例摳圖與 4.2. 視訊實例摳圖
-
實驗
5.1. 在影像資料上預訓練
5.2. 在視訊資料上訓練
-
討論與參考文獻
\ 補充材料
-
架構細節
-
影像摳圖
8.1. 資料集生成與準備
8.2. 訓練細節
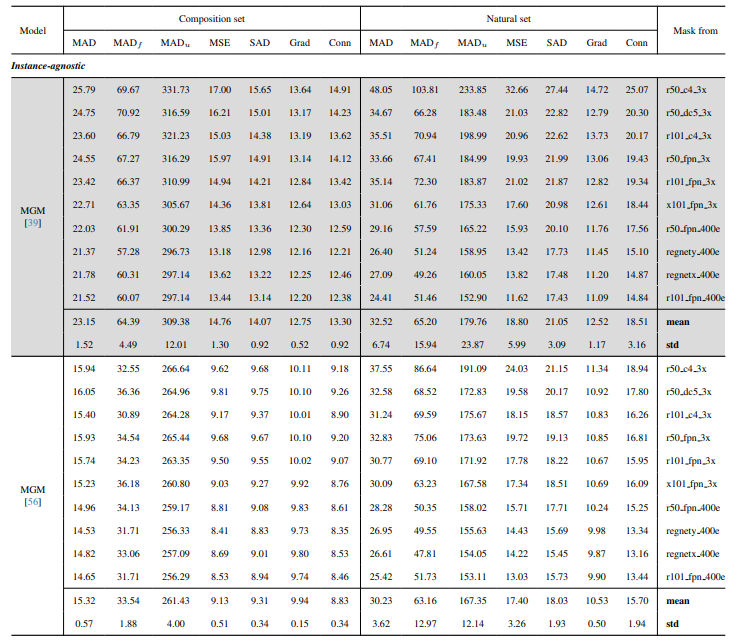
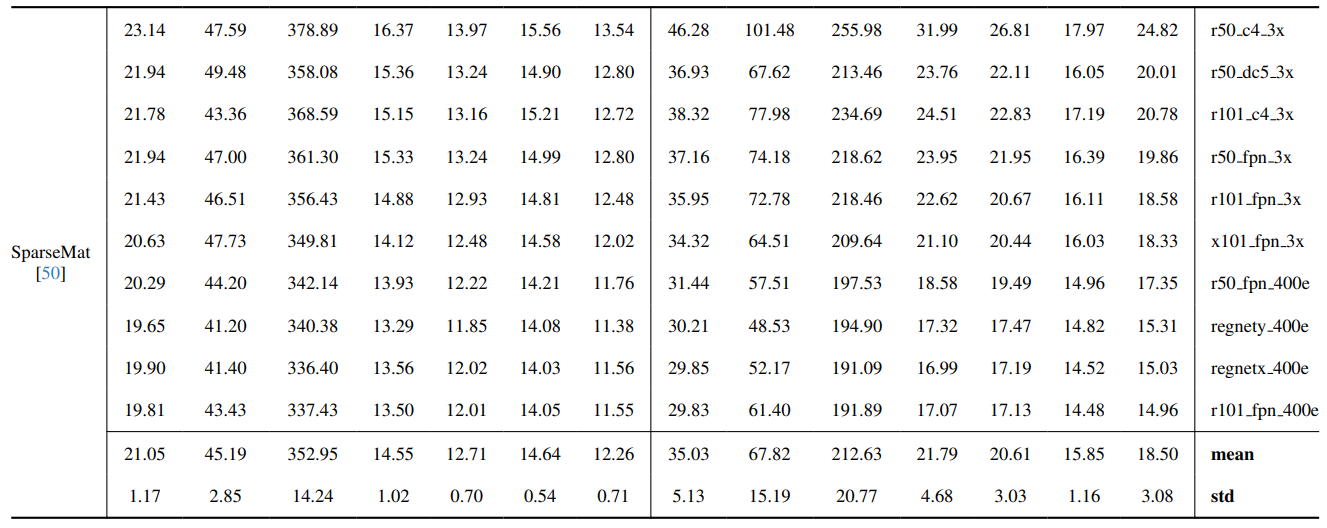
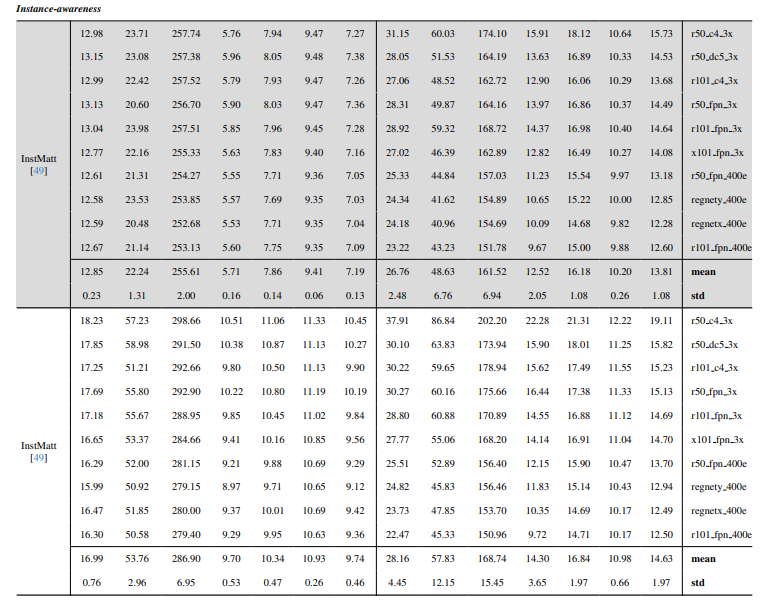
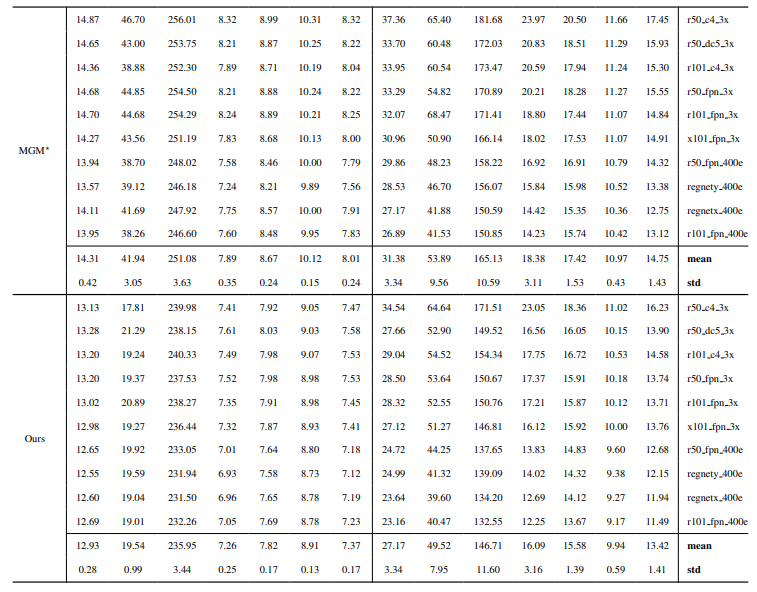
8.3. 定量細節
8.4. 更多自然影像的定性結果
-
視訊摳圖
9.1. 資料集生成
9.2. 訓練細節
9.3. 定量細節
9.4. 更多定性結果
8.4. 更多自然影像的定性結果
圖 13 展示了我們模型在具有挑戰性場景中的表現,特別是在準確渲染頭髮區域方面。我們的框架在細節保留方面持續優於 MGM⋆,尤其是在複雜的實例互動中。與 InstMatt 相比,我們的模型在模糊區域展現出更優越的實例分離和細節準確度。
\ 圖 14 和圖 15 展示了我們的模型和先前研究在涉及多個實例的極端情況下的表現。雖然 MGM⋆ 在密集實例場景中面臨雜訊和準確度的困擾,但我們的模型保持了高精確度。InstMatt 在沒有額外訓練資料的情況下,在這些複雜設置中顯示出局限性。
\ 我們遮罩引導方法的穩健性在圖 16 中得到進一步證明。在此,我們強調了 MGM 變體和 SparseMat 在預測遮罩輸入中缺失部分時所面臨的挑戰,而我們的模型解決了這些問題。然而,重要的是要注意,我們的模型並非設計為人體實例分割網路。如圖 17 所示,我們的框架遵循輸入引導,即使在同一遮罩中存在多個實例時,也能確保精確的 alpha 遮罩預測。
\ 最後,圖 12 和圖 11 強調了我們模型的泛化能力。該模型準確地從背景中提取人體主體和其他物體,展示了其在各種場景和物體類型中的多功能性。
\ 所有範例均為無真實標註的網路影像,並使用來自 r101fpn400e 的遮罩作為引導。
\ 
\ 
\ 
\ 
\ 
\ 
\ 
\ 
\ 
\ 
\
:::info 作者:
(1) Chuong Huynh,馬里蘭大學帕克分校 (chuonghm@cs.umd.edu);
(2) Seoung Wug Oh,Adobe Research (seoh,jolee@adobe.com);
(3) Abhinav Shrivastava,馬里蘭大學帕克分校 (abhinav@cs.umd.edu);
(4) Joon-Young Lee,Adobe Research (jolee@adobe.com)。
:::
:::info 本論文可在 arxiv 上取得,採用 CC by 4.0 Deed(姓名標示 4.0 國際)授權。
:::
\


您可能也會喜歡

並非漏洞:新加坡人工智慧出口管制讓中國合法取得美國人工智慧技術

比特幣永續合約:頂級交易所的多空比

NASA 剛向月球發射四名太空人——這對太空股意味著什麼



