

Teknik Detaylar: BSGAL Eğitimi, Swin-L Omurgası ve Dinamik Eşik Stratejisi
链接表
摘要和1 引言
-
相关工作
2.1. 生成式数据增强
2.2. 主动学习和数据分析
-
预备知识
-
我们的方法
4.1. 理想场景下的贡献估计
4.2. 批量流式生成主动学习
-
实验和5.1. 离线设置
5.2. 在线设置
-
结论、更广泛影响和参考文献
\
A. 实现细节
B. 更多消融实验
C. 讨论
D. 可视化
A. 实现细节
A.1. 数据集
我们选择LVIS (Gupta等, 2019)作为我们实验的数据集。LVIS是一个大规模实例分割数据集,包含约160,000张图像,涵盖1203个真实世界类别的超过200万个高质量实例分割标注。该数据集根据实例在图像中出现的频率进一步分为三类:稀有、常见和频繁。标记为"稀有"的实例出现在1-10张图像中,"常见"实例出现在11-100张图像中,而"频繁"实例出现在超过100张图像中。整个数据集呈长尾分布,与现实世界的数据分布非常相似,并广泛应用于多种设置,包括少样本分割(Liu等, 2023)和开放世界分割(Wang等, 2022; Zhu等, 2023)。因此,我们认为选择LVIS能更好地反映模型在现实场景中的性能。我们使用官方LVIS数据集划分,训练集约有100,000张图像,验证集有20,000张图像。
A.2. 数据生成
我们的数据生成和标注过程与Zhao等(2023)一致,这里简要介绍。我们首先使用StableDiffusion V1.5 (Rombach等, 2022a) (SD)作为生成模型。对于LVIS (Gupta等, 2019)中的1203个类别,我们为每个类别生成1000张图像,图像分辨率为512 × 512。生成的提示模板为"a photo of a single {CATEGORY NAME}"。我们分别使用U2Net (Qin等, 2020)、SelfReformer (Yun和Lin, 2022)、UFO (Su等, 2023)和CLIPseg (Luddecke和Ecker, 2022)来标注原始生成图像,并选择具有最高CLIP分数的掩码作为最终标注。为确保数据质量,CLIP分数低于0.21的图像被过滤掉作为低质量图像。在训练过程中,我们还采用Zhao等(2023)提供的实例粘贴策略进行数据增强。对于每个实例,我们随机调整其大小以匹配其类别在训练集中的分布。每张图像粘贴的最大实例数设置为20。
\ 此外,为了进一步扩展生成数据的多样性并使我们的研究更具普遍性,我们还使用了其他生成模型,包括DeepFloyd-IF (Shonenkov等, 2023) (IF)和Perfusion (Tewel等, 2023) (PER),每个模型每个类别生成500张图像。对于IF,我们使用作者提供的预训练模型,生成的图像是第二阶段的输出,分辨率为256×256。对于PER,我们使用的基础模型是StableDiffusion V1.5。对于每个类别,我们使用从训练集中裁剪的图像对模型进行微调,微调步骤为400步。我们使用微调后的模型生成图像。
\ 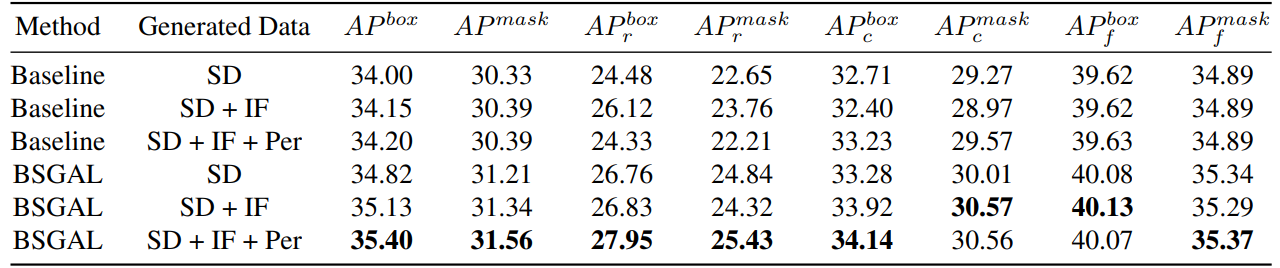
\ 我们还探索了使用不同生成数据对模型性能的影响(见表7)。我们可以看到,基于原始StableDiffusion V1.5,使用其他生成模型可以带来一些性能提升,但这种提升并不明显。具体来说,对于特定频率类别,我们发现IF对稀有类别有更显著的改进,而PER对常见类别有更显著的改进。这可能是因为IF数据更加多样化,而PER数据与训练集的分布更加一致。考虑到整体性能已经在一定程度上得到提高,我们最终采用SD + IF + PER的生成数据进行后续实验。
A.3. 模型训练
遵循Zhao等(2023),我们使用CenterNet2 (Zhou等, 2021)作为我们的分割模型,以ResNet-50 (He等, 2016)或Swin-L (Liu等, 2022)作为骨干网络。对于ResNet-50,最大训练迭代次数设置为90,000,模型初始化权重首先在ImageNet-22k上预训练,然后在LVIS (Gupta等, 2019)上微调,正如Zhao
\ 
\ 等(2023)所做的那样。我们在训练期间使用4个Nvidia 4090 GPU,批量大小为16。至于Swin-L,最大训练迭代次数设置为180,000,模型初始化权重在ImageNet-22k上预训练,因为我们的早期实验表明,与在LVIS上训练的权重相比,这种初始化可以带来轻微的改进。我们使用4个Nvidia A100 GPU进行训练,批量大小为16。此外,由于Swin-L参数数量庞大,保存梯度占用的额外内存很大,所以我们实际上使用算法2中的算法。
\ 其他未指定的参数也遵循与X-Paste (Zhao等, 2023)相同的设置,例如AdamW (Loshchilov和Hutter, 2017)优化器,初始学习率为1e−4。
A.4. 数据量
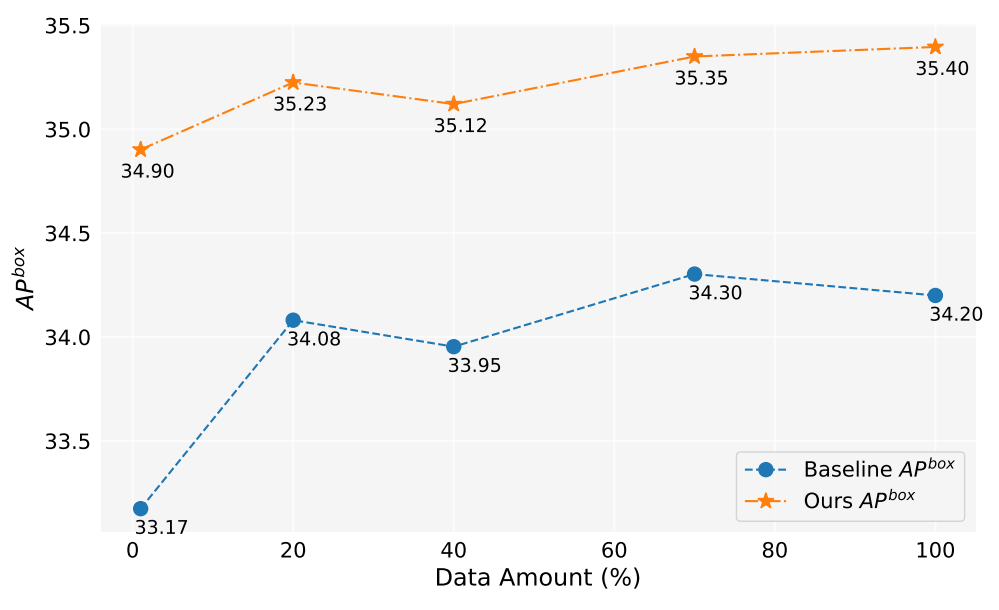
在这项工作中,我们生成了超过200万张图像。图5显示了使用不同数量生成数据(1%,10%,40%,70%,100%)时的模型性能。总体而言,随着生成数据量的增加,模型的性能也有所提高,但也存在一些波动。我们的方法始终优于基线,这证明了我们方法的有效性和稳健性。
A.5. 贡献估计
\ 因此,我们本质上是计算余弦相似度。然后我们进行了实验比较,如表8所示,
\ 
\ 
\ 我们可以看到,如果我们对梯度进行归一化,我们的方法会有一定的改进。此外,由于我们需要保持两个不同的阈值,很难确保接受率的一致性。因此,我们采用动态阈值策略,预设一个接受率,维护一个队列来保存前一次迭代的贡献,然后根据队列动态调整阈值,使接受率保持在预设的接受率。
A.6. 玩具实验
以下是在CIFAR-10上实施的具体实验设置:我们采用简单的ResNet18作为基线模型,并进行了200个epoch的训练,在原始训练集上训练后的准确率为93.02%。学习率设置为0.1,使用SGD优化器。动量为0.9,权重衰减为5e-4。我们使用余弦退火学习率调度器。构建的噪声图像如图6所示。随着噪声级别的升高,图像质量下降。值得注意的是,当噪声级别达到200时,图像变得非常难以识别。对于表1,我们使用Split1作为R,而G由'Split2 + Noise40'、'Split3 + Noise100'、'Split4 + Noise200'组成,
A.7. 仅前向传播一次的简化
\
:::info 作者:
(1) 朱慕之,来自中国浙江大学,贡献相同;
(2) 范成祥,来自中国浙江大学,贡献相同;
(3) 陈浩,中国浙江大学 (haochen.cad@zju.edu.cn);
(4) 刘洋,中国浙江大学;
(5) 毛伟安,中国浙江大学和澳大利亚阿德莱德大学;
(6) 徐晓刚,中国浙江大学;
(7) 沈春华,中国浙江大学 (chunhuashen@zju.edu.cn)。
:::
:::info 本论文可在arxiv上获取,遵循CC BY-NC-ND 4.0 Deed (署名-非商业性使用-禁止演绎 4.0 国际)许可协议。
:::
\
Ayrıca Şunları da Beğenebilirsiniz

SEC Başkanı, Kripto Para Tabanlı Dönüşüm Ortasında Bitcoin'in Küresel Finansal Sistemin Temeli Olacağını Öngörüyor

CryptoRank'ın Sonbahar Raporunda Büyük Dijital Varlıklar Düşüşte
