

アダプティブバッチ処理でデータパイプラインを5倍速く
データ変換フローで大量のLLM呼び出しを行っていますか?
CocoIndexがお役に立てるかもしれません。超高性能なRustエンジンを搭載し、今ではアダプティブバッチ処理をすぐに利用できます。これによりAIネイティブワークフローのスループットが約5倍(≈80%の実行時間短縮)向上しました。さらに素晴らしいことに、バッチ処理は自動的に行われ、トラフィックに適応してGPUを最大限に活用するため、コードを変更する必要はありません。
Cocoindexにアダプティブバッチ処理サポートを構築する過程で学んだことをご紹介します。
まず、あなたの疑問に答えましょう。
なぜバッチ処理で処理速度が向上するのか?
-
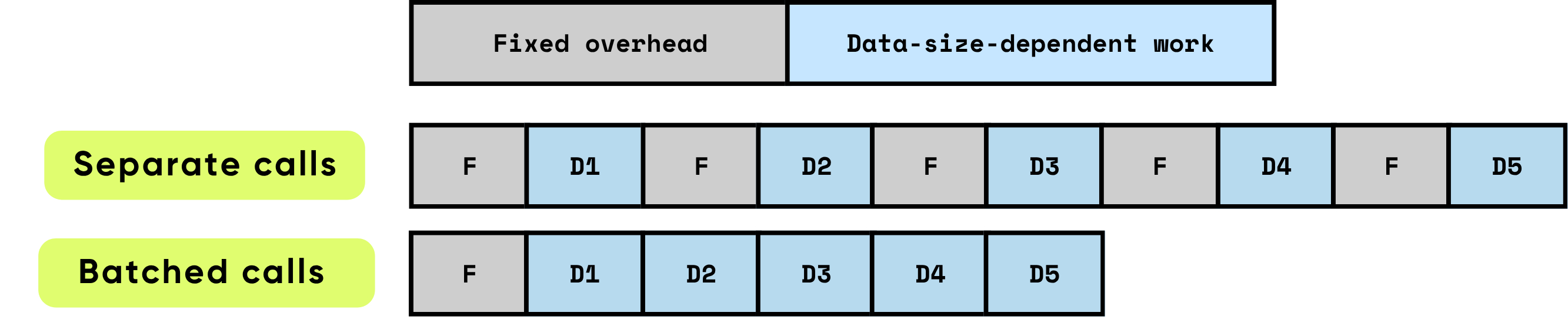
呼び出しごとの固定オーバーヘッド:実際の計算が始まる前に必要な準備作業や管理作業のことです。例えば、GPUカーネル起動のセットアップ、PythonからC/C++への移行、タスクのスケジューリング、メモリ割り当てと管理、フレームワークによる記録作業などが含まれます。これらのオーバーヘッド作業は入力サイズにほとんど依存しませんが、呼び出しごとに全額支払う必要があります。
-
データ依存の作業:計算のこの部分は、入力のサイズと複雑さに直接比例します。モデルによる浮動小数点演算(FLOPs)、メモリ階層間のデータ移動、トークン処理、その他の入力固有の操作が含まれます。固定オーバーヘッドとは異なり、このコストは処理されるデータ量に比例して増加します。
アイテムを個別に処理すると、固定オーバーヘッドがアイテムごとに繰り返し発生し、特にアイテムごとの計算が比較的小さい場合、すぐに総実行時間を支配してしまいます。対照的に、複数のアイテムをバッチで一緒に処理すると、このオーバーヘッドのアイテムごとの影響が大幅に軽減されます。バッチ処理により、固定コストを多くのアイテムに分散させながら、データ依存の作業の効率を向上させるハードウェアとソフトウェアの最適化も可能になります。これらの最適化には、GPUパイプラインのより効果的な活用、キャッシュの活用向上、カーネル起動の削減などが含まれ、すべてがスループットの向上と全体的な遅延の低減に貢献します。
バッチ処理は計算効率とリソース活用の両方を最適化することで、パフォーマンスを大幅に向上させます。複数の相乗効果をもたらします:
-
一回限りのオーバーヘッドの償却:各関数やAPI呼び出しには固定オーバーヘッドがあります — GPUカーネル起動、PythonからC/C++への移行、タスクスケジューリング、メモリ管理、フレームワークの記録作業など。アイテムをバッチで処理することで、このオーバーヘッドが多くの入力に分散され、アイテムごとのコストが劇的に削減され、繰り返しのセットアップ作業が排除されます。
-
GPU効率の最大化:より大きなバッチにより、GPUは一般的に一般行列-行列乗算(GEMM)として実装される密で高度に並列な行列乗算として操作を実行できます。このマッピングにより、ハードウェアは並列計算ユニットを最大限に活用し、アイドルサイクルを最小限に抑え、ピークスループットを達成する高い利用率で実行されます。小さな、バッチ処理されていない操作では、GPUの多くが十分に活用されず、高価な計算能力が無駄になります。
-
データ転送オーバーヘッドの削減:バッチ処理によりCPU(ホスト)とGPU(デバイス)間のメモリ転送の頻度が最小限に抑えられます。ホストからデバイス(H2D)およびデバイスからホスト(D2H)の操作が少なくなるということは、データの移動に費やす時間が少なくなり、実際の計算に費やす時間が増えることを意味します。これは高スループットシステムにとって重要であり、メモリ帯域幅が生の計算能力よりも制限要因になることがよくあります。
これらの効果が組み合わさると、スループットが桁違いに向上します。バッチ処理により、多くの小さな非効率な計算が、現代のハードウェア機能を最大限に活用する大きな高度に最適化された操作に変換されます。AIワークロード — 大規模言語モデル、コンピュータビジョン、リアルタイムデータ処理を含む — にとって、バッチ処理は単なる最適化ではなく、スケーラブルな本番品質のパフォーマンスを達成するために不可欠です。
通常のPythonコードでのバッチ処理の例
非バッチ処理コード – シンプルだが効率が低い
パイプラインを構成する最も自然な方法は、データを一つずつ処理することです。例えば、このような二層のループです:
for file in os.listdir(directory): content = file.read() chunks = split_into_chunks(content) for chunk in chunks: vector = model.encode([chunk.text]) # one item at a time index.upsert(file_id=file.name, chunk_offset=chunk.offset, vector=vector)
これは読みやすく理解しやすいです:各チャンクが複数のステップをまっすぐに流れていきます。
手動バッチ処理 – より効率的だが複雑
バッチ処理で高速化できますが、最もシンプルな「すべてを一度にバッチ処理する」バージョンでさえ、コードはかなり複雑になります:
# 1) ペイロードを収集し、それぞれの出所を記憶する batch_texts = [] metadata = [] # (file_id, chunk_id) for file in os.listdir(directory): content = file.read() chunks = split_into_chunks(content) for chunk in chunks: batch_texts.append(chunk.text) metadata.append((file.name, chunk.offset)) # 2) 一括バッチ呼び出し(ライブラリは内部でミニバッチ処理を行う) vectors = model.encode(batch_texts) # 3) 結果をそれぞれのソースに戻す for (file_name, chunk_offset), vector in zip(metadata, vectors): index.upsert(file_id=file.name, chunk_offset=chunk.offset, vector=vector)
さらに、すべてを一度にバッチ処理することは通常理想的ではありません。なぜなら、次のステップはすべてのデータに対してこのステップが完了した後でしか開始できないからです。
CocoIndexのバッチ処理サポート
CocoIndexはこのギャップを埋め、両方の世界の良いところを得ることができます – 自然なフローに従ってコードのシンプルさを保ちながら、CocoIndexランタイムが提供するバッチ処理の効率性を得ることができます。
すでに以下の組み込み関数に対してバッチ処理サポートを有効にしています:
- EmbedText
- SentenceTransformerEmbed
- ColPaliEmbedImage
- ColPaliEmbedQuery
APIは変更されません。既存のコードは変更なしで動作し、自然なフローに従いながらバッチ処理の効率性を享受できます。
カスタム関数の場合、バッチ処理の有効化は次のように簡単です:
- カスタム関数デコレータで
batching=Trueを設定します。 - 引数と戻り値の型を
listに変更します。
例えば、画像のサムネイルを作成するAPIを呼び出すカスタム関数を作成したい場合:
@cocoindex.op.function(batching=True) def make_image_thumbnail(self, args: list[bytes]) -> list[bytes]: ...
:::tip 詳細についてはバッチ処理のドキュメントをご覧ください。
:::
CocoIndexのバッチ処理方法
一般的なアプローチ
バッチ処理は、着信リクエストをキューに収集し、それらを単一のバッチとしてフラッシュする適切なタイミングを決定することで機能します。そのタイミングは非常に重要です — 適切に行えば、スループット、レイテンシー、リソース使用率のバランスを一度に取ることができます。
広く使用されている2つのバッチ処理ポリシーが主流です:
- 時間ベースのバッチ処理(W ミリ秒ごとにフラッシュ):このアプローチでは、システムはW ミリ秒の固定ウィンドウ内に到着したすべてのリクエストをフラッシュします。
-
利点:任意のリクエストの最大待機時間は予測可能であり、実装は簡単です。トラフィックが少ない時でも、リクエストがキューに無期限に残ることはありません。
-
欠点:トラフィックが疎らな期間中、アイドル状態のリクエストがゆっくりと蓄積され、早期到着に対するレイテンシーが増加します。さらに、最適なウィンドウWはワークロードの特性によって異なることが多く、レイテンシーとスループットの間で適切なバランスを取るために慎重な調整が必要です。
- サイズベースのバッチ処理(Kアイテムがキューに入ったらフラッシュ):ここでは、キューが事前定義された数のアイテムKに達すると、バッチがトリガーされます。
- 利点:バッチサイズが予測可能であり、メモリ管理とシステム設計が簡素化されます。各バッチが消費するリソースについて推論しやすくなります。
- 欠点:トラフィックが少ない場合、リクエストが長期間キューに残り、最初に到着したアイテムのレイテンシーが増加する可能性があります。時間ベースのバッチ処理と同様に、最適なKはワークロードパターンに依存し、経験的な調整が必要です。
多くの高性能システムはハイブリッドアプローチを採用しています:時間ウィンドウWが期限切れになるか、キューがサイズKに達したとき — どちらか早い方でバッチをフラッシュします。この戦略は両方の方法の利点を取り入れ、疎らな


関連コンテンツ

南アフリカ観光業のGDPが9%達成、10.3%成長を目標に

FlokiPrice予測が92%下落、Pepetoが上昇




