

今日のAIが実際に「思考」できない5つの驚くべき方法

大規模言語モデル(LLM)は能力が爆発的に向上し、自然言語理解からコード生成までのタスクで驚くべきパフォーマンスを示しています。私たちは日常的にそれらと対話し、その流暢さは驚異的で、私たちを人工知能の不気味の谷に真っ直ぐに置いています。しかし、この洗練されたパフォーマンスは本物の思考と同等なのでしょうか、それとも単なるハイテクな幻想なのでしょうか?
\ 増え続ける研究は、能力の幕の裏には深遠で直感に反する限界があることを示唆しています。この記事では、AIのパフォーマンスと真の人間のような理解の間の溝を露呈させる最も重要な5つの失敗について探ります。
彼らはより懸命に推論するのではなく、単に崩壊する
アップルリサーチの最近の論文「思考の幻想」は、Chain-of-Thoughtのような技術を使用する最も高度な「大規模推論モデル」(LRM)にさえ重大な欠陥があることを明らかにしています。この研究は、これらのモデルが真に推論しているのではなく、問題が十分に複雑になると壁にぶつかる洗練されたシミュレーターであることを示しています。
\ 研究者たちはハノイの塔パズルを使用してモデルをテストし、パズルの複雑さに基づいて3つの異なるパフォーマンス領域を特定しました:
\
- 低複雑性(3枚のディスク):標準的な非推論モデルは、「思考する」LRMモデルと同等、あるいはそれ以上のパフォーマンスを示しました。
- 中複雑性(6枚のディスク):より長い思考の連鎖を生成するLRMは明確な優位性を示しました。
- 高複雑性(7枚以上のディスク):両方のモデルタイプは「完全な崩壊」を経験し、その精度はゼロに急落しました。
\
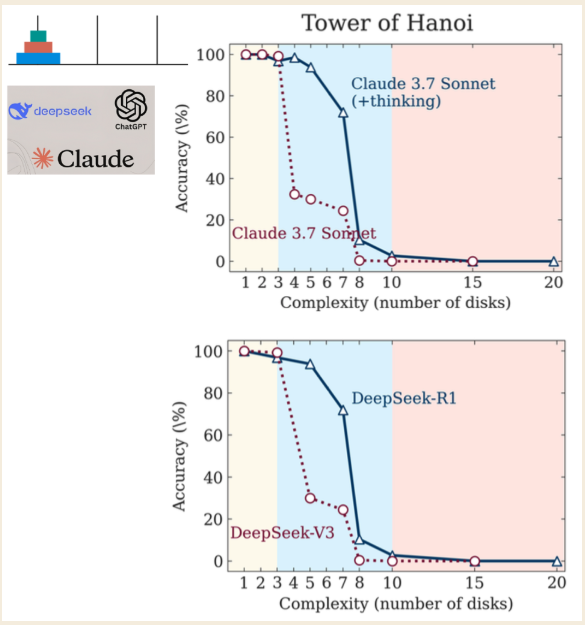
最も直感に反する発見は、問題が難しくなるにつれてモデルの「思考」が少なくなることでした。さらに厳しいことに、パズルを解くために必要なアルゴリズムを明示的に与えられても、正しく計算することができません。これは、プレッシャーの下でルールを適用する根本的な能力の欠如を示唆しており、最も重要な時に崩壊する思考の空虚な模倣です。(研究者たちは、ライバルのAIラボであるAnthropicが異議を唱えているものの、それらは発見の根本的な反論というよりも些細な不満に過ぎないと指摘しています。)
\ アリゾナ大学の研究者たちが述べているように、この行動は幻想の本質を捉えています:
…LLMは原則に基づいた推論者ではなく、むしろ推論のようなテキストの洗練されたシミュレーターであることを示唆しています。
彼らの「思考の連鎖」はしばしば蜃気楼である
思考の連鎖(CoT)は、LLMが最終的な回答を提供する前にステップバイステップの「推論」を書き出すプロセスであり、精度を向上させ内部ロジックを明らかにするように設計された機能です。しかし、LLMが基本的な算術をどのように処理するかを分析した最近の研究では、このプロセスがしばしば「脆い蜃気楼」であることが示されています。
\ 驚くべきことに、CoTの推論ステップとモデルが提供する最終的な回答の間には大きな不一致があります。単純な足し算を含むタスクでは、衝撃的な発見がありました:サンプルの60%以上で、モデルは何らかの方法で、不思議なことに、正しい最終的な答えにつながる不正確な推論ステップを生成しました。
\ これは、数学のテストで意味不明な作業を示しながらも、奇跡的に正しい最終的な数字を書き留める学生と同等です。彼らが教材を理解していると結論付けることはないでしょう;答えをコピーしたと疑うでしょう。AIでは、これは「推論」がしばしば事後的な正当化であり、本物の思考プロセスではないことを示唆しています。これはスケールアップによって修正されるバグではありません;この問題はより高度なモデルでさらに悪化し、この矛盾した行動の割合はGPT-4で74%に増加します。
\ モデルの内部「思考プロセス」が蜃気楼であるなら、実際の複雑な問題を解決するよう強制されたときに何が起こるのでしょうか?しばしば、それは狂気に陥ります。
彼らは「狂気への降下」ループに閉じ込められる
コードのデバッグのような複雑なタスクにLLMを使用する場合、危険なパターンが現れることがあります:「狂気への降下」または「幻覚ループ」です。これは、プログラミングエラーを修正しようとするLLMが、終了しない不合理なループに閉じ込められるフィードバックサイクルです。それは、もっともらしく見える修正を提案しますが、それは失敗し、別の解決策を求められると、しばしば元のエラーを再導入し、ユーザーを実りのないサイクルに閉じ込めます。
\ プログラマーにコードのデバッグを課した研究では、AI支援ワークフローに対する衝撃的なトレンドが明らかになりました。結果は明確でした:AI支援なしのプログラマーは、LLMを助けに使用したグループよりも、より多くのタスクを正しく解決し、より少ないタスクを間違って解決しました。
\ これを考えてみてください:複雑なデバッグタスクでは、最先端のAIアシスタントを持つことは単に役に立たないだけでなく、積極的に有害であり、AIを全く持たない場合よりも悪い結果につながりました。AIを使用する参加者は頻繁にこれらの実りのないループに閉じ込められ、概念的に根拠のない修正に時間を浪費しました。研究者たちはまた、「ノイズの多い解決策」問題を特定しました。これは、正しい修正が無関係な提案の中に埋もれており、人間のフラストレーションの完璧なレシピとなっています。この欠陥のある「支援」は、特にリスクが高い場合に、AIの印象的な外観が深く信頼できないコアを隠すことができることを強調しています。
彼らの印象的なベンチマークは欠陥の基盤の上に構築されている
AI企業が新しいモデルをリリースする際、彼らはその優位性を証明するために印象的なベンチマークスコアを指摘します。しかし、より詳しく見ると、はるかに魅力的でない絵が明らかになることがあります。
\ GitHubの実世界のソフトウェア問題を修正するLLMの能力を測定するために使用されるSWE-bench(ソフトウェアエンジニアリングベンチマーク)は、主要な事例研究です。ヨーク大学からの独立した研究は、モデルの認識された能力を大幅に膨らませる重大な欠陥を発見しました:
\
- 解決策の漏洩(「カンニング」):成功したパッチの32.67%で、正しい解決策は問題レポート自体にすでに提供されていました。
- 弱いテスト:モデルが「合格」したケースの31.08%で、検証テストは修正が正しいことを実際に確認するには弱すぎました。
\ これらの欠陥のあるインスタンスがフィルタリングされると、トップモデル(SWE-Agent + GPT-4)の実世界のパフォーマンスは急落しました。その解決率は宣伝された12.47%からわずか3.97%に低下しました。さらに、ベンチマークの問題の94%以上がLLMの知識カットオフ日以前に作成されており、データ漏洩に関する深刻な疑問を提起しています。
\ これは厄介な現実を明らかにしています:ベンチマークはしばしば、実世界の精査の下で崩れる最良のケース、研究室で育てられたシナリオを提示するマーケティングツールです。宣伝されたパワーと検証されたパフォーマンスの間のギャップはひび割れではありません;それは峡谷です。
彼らはルールをマスターするが、根本的に理解が欠けている
上記の技術的な失敗がすべて修正されたとしても、より深い、より哲学的な障壁が残っています。LLMは人間の知性の核心的な要素を欠いています。哲学者たちが意識と意図性について議論する一方で、多くの議論は、合理性、つまり普遍的な概念を把握し論理的に推論する能力が、人間に固有でAIには欠けている鍵となる側面であることを示唆しています。
\ この考えは、物理学者のロジャー・ペンローズによって強化されています。彼はゲーデルの不完全性定理を使用して、人間の数学的理解がアルゴリズム的ルールの固定セットを超越していると主張しています。任意のアルゴリズムを有限のルールブックと考えてください。ゲーデルの定理は、人間の数学者が常にルールブックを外側から見て、ルールブック自体が証明できない真実を理解できることを示しています。
\ 私たちの心は本の中のルールに従うだけではありません;私たちは本全体を読み、その限界を把握することができます。この洞察の能力、この「計算不可能な」理解は、人間の認知を最も高度なAIからも分けるものです。
\ LLMはアルゴリズムと統計的パターンに基づいてシンボルを操作するマスターです。しかし、彼らは本物の理解に必要な意識を持っていません。ある強力な議論が結論付けるように:
魔術師のトリック
LLMは不気味な精度でインテリジェントな行動をシミュレートできる否定できない強力なツールですが、増え続ける証拠は、彼らが本物の思想家というよりも洗練されたシミュレーターであることを示しています。彼らのパフォーマンスは壮大な幻想であり、プレッシャーの下で崩壊し、自身のロジックに矛盾し、欠陥のある指標に依存する能力の目を見張るようなスペクタクルです。それは魔術師のトリック(一見不可能に見える)に似ていますが、最終的には実際の魔法ではなく、巧妙な技術に基づいた幻想です。私たちがこれらのシステムを私たちの世界に統合し続けるにつれて、私たちは批判的であり続け、本質的な質問をする必要があります:
\ これらのAIマシンがより難しい問題で崩壊するとき、アルゴリズムとルールを与えても、彼らは実際


関連コンテンツ

アーサー・ヘイズ氏、3か月ぶりにHYPEを110万ドル分購入

10億ドル台から急落した暗号資産プロジェクト




