

データ不足解決策:CT-超音波変換のためのS-CycleGAN
リンク一覧
概要と1 はじめに
-
関連研究
-
問題設定
-
方法論
4.1. 決定境界を意識した蒸留
4.2. 知識の統合
-
実験結果と5.1. 実験セットアップ
5.2. 最先端手法との比較
5.3. アブレーション研究
-
結論と今後の課題および参考文献
\
補足資料
- IILにおけるKCEMAメカニズムの理論的分析の詳細
- アルゴリズム概要
- データセットの詳細
- 実装の詳細
- ダスト処理された入力画像の可視化
- その他の実験結果
概要
インスタンス増分学習(IIL)は、同じクラスのデータで継続的に学習することに焦点を当てています。クラス増分学習(CIL)と比較して、IILは破滅的忘却(CF)の影響が少ないため、あまり研究されていません。しかし、知識の保持に加えて、クラス空間が常に事前定義されている実世界の展開シナリオでは、以前のデータが利用できない可能性がある中での継続的かつコスト効率の良いモデル改善がより本質的な要求です。そのため、私たちはまず、新しい観測データのみでCFに抵抗しながらモデルのパフォーマンスを向上させるという、新しくより実用的なIIL設定を定義します。新しいIIL設定では、2つの問題に取り組む必要があります:1)古いデータにアクセスできないことによる悪名高い破滅的忘却、2)コンセプトドリフトによる新しい観測データへの既存の決定境界の拡大。これらの問題に対処するために、私たちの重要な洞察は、古い境界を維持しながら、失敗ケースに対して決定境界を適度に拡大することです。そこで、学生が新しい知識を学ぶのを容易にするために、教師への知識統合を伴う新しい決定境界を意識した蒸留方法を提案します。また、既存のデータセットCifar-100とImageNetにベンチマークを確立しました。特筆すべきは、広範な実験により、教師モデルが学生モデルよりも優れた増分学習者になり得ることが示されたことで、これは学生を主役として扱う以前の知識蒸留ベースの手法を覆すものです。
1. はじめに
近年、画像分類、セグメンテーション、検出などの様々なタスクに対して、多くの優れたディープラーニングベースのネットワークが提案されています。これらのネットワークはトレーニングデータに対して良好なパフォーマンスを示しますが、実世界のアプリケーションでトレーニングされていない新しいデータに対しては必然的に失敗します。これらの新しいデータに対して、展開されたモデルのパフォーマンスを継続的かつ効率的に向上させることは不可欠な要求です。蓄積されたすべてのデータを使用してネットワークを再トレーニングする現在の解決策には2つの欠点があります:1)データサイズの増加に伴い、トレーニングコストが毎回高くなります(例えば、より多くのGPU時間とより大きなカーボンフットプリント[20])、2)プライバシーポリシーやデータストレージの予算制限のため、古いデータにアクセスできなくなる場合があります。古いデータがほとんどまたはまったく利用できない場合、新しいデータでディープラーニングモデルを再トレーニングすると、常に古いデータに対するパフォーマンスの低下、つまり破滅的忘却(CF)問題が発生します。CF問題に対処するために、増分学習[4, 5, 22, 29](継続学習とも呼ばれる)が提案されています。増分学習はディープラーニングモデルの実用的価値を大幅に向上させ、激しい研究の関心を集めています。
\ 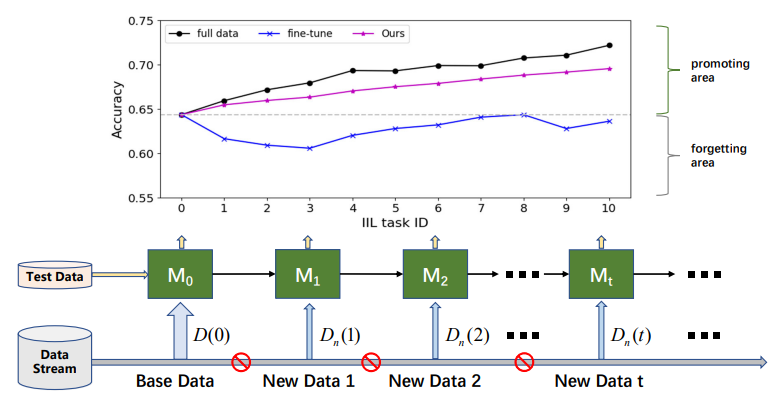
\ 新しいデータが既存のクラスから来るかどうかによって、増分学習は3つのシナリオに分けることができます[16, 17]:すべての新しいデータが既存のクラスに属するインスタンス増分学習(IIL)[3, 16]、新しいデータが異なるクラスラベルを持つクラス増分学習(CIL)[4, 12, 15, 22]、そして新旧両方のクラスからの新しい観測データで構成されるハイブリッド増分学習[6, 30]です。CILと比較して、IILはCFの影響を受けにくいため、比較的未探索です。LomonacoとMaltoni[16]は、早期停止を伴う微調整がIILでのCF問題をうまく抑制できると報告しています。しかし、図1に示すように、古いトレーニングデータにアクセスできず、新しいデータが古いデータよりもはるかに小さいサイズの場合、この結論は常に成り立つわけではありません。微調整は、新しい観測データに対応するために決定境界を拡大するのではなく、決定境界のシフトをもたらすことがよくあります。古い知識を保持することに加えて、実際の展開ではIILでの効率的なモデル改善がより重要です。例えば、工業製品の欠陥検出では、欠陥のクラスは常に既知のカテゴリに限定されています。しかし、それらの欠陥の形態は時間とともに変化します。未見の欠陥に対する失敗は、欠陥製品が市場に流れるのを避けるために、タイムリーかつ効率的に修正されるべきです。残念ながら、既存の研究は主に古いデータに関する知識の保持に焦点を当てており、新しい観測データによる知識の豊富化にはあまり注目していません。
\ 本論文では、既存のクラスの新しい観測データを用いて訓練済みモデルを迅速かつコスト効率良く強化するために、まず新しいIIL設定を古いデータにアクセスせずに、学習した知識を保持しながら新しい観測データに対するモデルのパフォーマンスを向上させると定義します。簡単に言えば、新しいデータのみを活用して既存のモデルを向上させ、蓄積されたすべてのデータで再トレーニングされたモデルに匹敵するパフォーマンスを達成することを目指しています。新しいIILは、古いデータと比較した色や形状の変化など、新しい観測データによって引き起こされるコンセプトドリフト[6]のために困難です。したがって、新しいIIL設定では2つの問題に取り組む必要があります:1)古いデータにアクセスできないことによる悪名高い破滅的忘却、2)新しい観測データへの既存の決定境界の拡大。
\ 新しいIIL設定での上記の問題に対処するために、教師-学生構造に基づく新しいIILフレームワークを提案します。提案されたフレームワークは、決定境界を意識した蒸留(DBD)プロセスと知識統合(KC)プロセスで構成されています。DBDにより、学生モデルは既存のクラス間決定境界を意識しながら新しい観測データから学習することができ、モデルが知識を強化すべき場所と保持すべき場所を決定できるようになります。しかし、IILでは古いデータにアクセスできないため、境界付近に十分なサンプルがない場合、決定境界は追跡不可能です。これを克服するために、隠れた足跡を明らかにするために床に小麦粉をまくという実践からインスピレーションを得ました。同様に、入力空間を汚染し、蒸留のために学習された決定境界を明らかにするためにランダムなガウスノイズを導入します。境界蒸留で学生モデルをトレーニングする間、更新された知識はEMAメカニズム[28]を用いて断続的かつ繰り返し教師モデルに統合されます。教師モデルをターゲットモデルとして利用することは先駆的な試みであり、その実現可能性は理論的に説明されています。
\ 新しいIIL設定に従って、CILで一般的に使用されている既存のデータセット(Cifar-100[11]やImageNet[24]など)のトレーニングセットを再編成してベンチマークを確立します。モデルは各増分フェーズでテストデータと利用不可能なベースデータの両方で評価されます。私たちの主な貢献は以下のようにまとめることができます:1)新しい観測データに対する迅速かつコスト効率の良いモデル改善を求めるために新しいIIL設定を定義し、ベンチマークを確立しました;2)学習した知識を保持しながら新しいデータでそれを豊かにするための新しい決定境界を意識した蒸留方法を提案しました;3)より良いパフォーマンスと一般化能力を達成するために、学生から教師モデルへの学習知識を創造的に統合し、理論的にその実現可能性を証明しました;そして4)広範な実験により、提案された方法は新しいデータのみで知識をうまく蓄積する一方、既存の増分学習方法のほとんどが失敗したことを示しました。
\
:::info この論文はarxivで入手可能であり、CC BY-NC-ND 4.0 Deed(Attribution-Noncommercial-Noderivs 4.0 International)ライセンスの下で公開されています。
:::
:::info 著者:
(1) Qiang Nie, 香港科技大学(広州);
(2) Weifu Fu, テンセントYoutuラボ;
(3) Yuhuan Lin, テンセントYoutuラボ;
(4) Jialin Li, テンセントYoutuラボ;
(5) Yifeng Zhou, テンセントYoutuラボ;
(6) Yong Liu, テンセントYoutuラボ;
(7) Qiang Nie, 香港科技大学(広州);
(8) Chengjie Wang, テンセントYoutuラボ。
:::
\





