

アブレーション研究がRECKONINGのパフォーマンスに動的レートの必要性を確認
リンク一覧
概要と1. はじめに
-
背景
-
方法
-
実験
4.1 マルチホップ推論性能
4.2 ディストラクタを含む推論
4.3 実世界の知識への一般化
4.4 実行時間分析
4.5 知識の記憶
-
関連研究
-
結論、謝辞、参考文献
\ A. データセット
B. ディストラクタを含むインコンテキスト推論
C. 実装の詳細
D. 適応型学習率
E. 大規模言語モデルを用いた実験
D 適応型学習率
先行研究[3, 4]では、ステップとパラメータ間で共有される固定学習率はシステムの一般化性能に寄与しないことが示されています。代わりに、[3]では
\ 
\ 
\ 内部ループの各ネットワーク層と各適応ステップに対する学習率を学習することを推奨しています。層パラメータは各ステップで学習率を動的に調整することを学習できます。内部ループで学習率αを適応的に制御するために、αを調整可能な変数のセットとして定義します:α = {α0, α1, …αL}、ここでLは層の数であり、すべてのl = 0, …, Lに対して、αlは事前定義された内部ループステップ数Nが与えられたN要素のベクトルです。内部ループの更新式は次のようになります
\ 
\ 
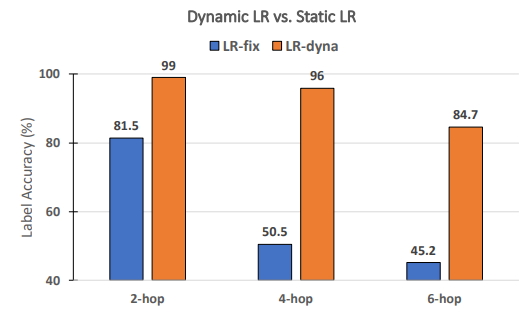
\ RECKONINGの性能に動的学習率は必要か? メタ学習に関する先行研究[3, 4]に従い、RECKONINGのためにステップごと・層ごとの学習率のセットを動的に学習します。このアブレーション研究では、内部ループの動的学習率が外部ループの推論性能を効果的に向上させるかどうかを分析します。同様に、他の実験設定を固定し、内部ループのステップ数を4に設定します。図8に示すように、静的学習率(つまり、すべての層と内部ループステップが一定の学習率を共有する)を使用すると、性能は大幅に低下します(平均34.2%の低下)。この性能低下は、より多くの推論ホップを必要とする質問でより顕著になります(4ホップで45.5%の低下、6ホップで39.5%の低下)。これは、フレームワークの内部ループで動的学習率を使用することの重要性を示しています。
\ 
\
:::info 著者:
(1) Zeming Chen, EPFL (zeming.chen@epfl.ch);
(2) Gail Weiss, EPFL (antoine.bosselut@epfl.ch);
(3) Eric Mitchell, Stanford University (eric.mitchell@cs.stanford.edu)';
(4) Asli Celikyilmaz, Meta AI Research (aslic@meta.com);
(5) Antoine Bosselut, EPFL (antoine.bosselut@epfl.ch).
:::
:::info この論文は arxivで入手可能 であり、CC BY 4.0 DEEDライセンスの下で公開されています。
:::
\


関連コンテンツ

Matrixdock、XAUmゴールドトークン準備金に関する第2回独立監査報告書を公開
币安人生が63%急騰、24時間の取引高が時価総額の66%に到達




