

Totoが多変量予測のためのマルチヘッドアテンションを再考する方法

リンク一覧
- 背景
- 問題提起
- モデルアーキテクチャ
- トレーニングデータ
- 結果
- 結論
- 影響に関する声明
- 今後の方向性
- 貢献
- 謝辞と参考文献
付録
3 モデルアーキテクチャ
Totoはデコーダーのみの予測モデルです。このモデルは文献から最新の技術を多く採用し、マルチヘッドアテンションを多変量時系列データに適応させる新しい手法を導入しています(図1)。
\ 3.1 Transformerの設計
\ 時系列予測のためのTransformerモデルは、エンコーダー-デコーダー[12, 13, 21]、エンコーダーのみ[14, 15, 17]、デコーダーのみのアーキテクチャ[19, 23]など様々なものが使用されてきました。Totoでは、デコーダーのみのアーキテクチャを採用しています。デコーダーアーキテクチャはスケーラビリティが高く[25, 26]、任意の予測期間を可能にします。因果関係のある次のパッチ予測タスクも事前トレーニングプロセスを簡素化します。
\ 私たちは最新の大規模言語モデル(LLM)アーキテクチャからの技術を使用しています。これには事前正規化[27]、RMSNorm[28]、SwiGLUフィードフォワード層[29]が含まれます。
\ 3.2 入力埋め込み
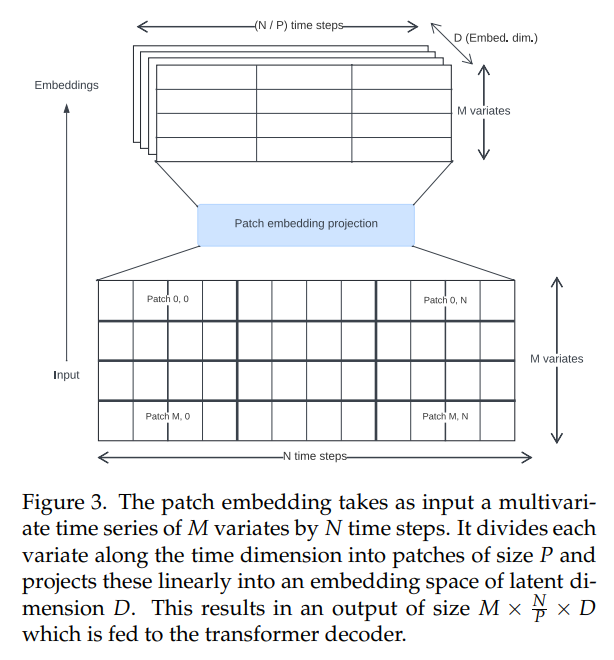
\ 文献における時系列Transformerは、入力埋め込みを作成するために様々なアプローチを使用してきました。私たちはVision Transformer[30, 31]で最初に導入され、PatchTST[14]によって時系列の文脈で普及した、重複しないパッチ投影(図3)を使用しています。Totoは固定パッチサイズ32でトレーニングされました。
\ 
\ 3.3 アテンションメカニズム
\ 観測可能性メトリクスは、多くの場合、高カーディナリティの多変量時系列です。したがって、理想的なモデルは多変量予測をネイティブに処理できる必要があります。時間次元(「時間方向」の相互作用と呼ぶもの)とチャネル次元(Datadogプラットフォームでメトリクスの異なるグループやタグセットを「空間」次元として説明する慣習に従い、「空間方向」の相互作用と呼ぶもの)の両方で関係を分析できる必要があります。
\ 空間と時間方向の相互作用の両方をモデル化するために、従来のマルチヘッドアテンションアーキテクチャ[11]を1次元から2次元に適応させる必要があります。文献ではこれを行うためにいくつかのアプローチが提案されています:
\ • チャネルの独立性を仮定し、時間次元でのみアテンションを計算する[14]。これは効率的ですが、空間方向の相互作用に関するすべての情報を捨ててしまいます。
\ • 空間次元でのみアテンションを計算し、時間次元ではフィードフォワードネットワークを使用する[17, 18]。
\ • 変量を時間次元に沿って連結し、すべての空間/時間位置間で完全なクロスアテンションを計算する[15]。これはあらゆる空間と時間の相互作用を捉えることができますが、計算コストが高くなります。
\ • 「因数分解アテンション」を計算する。各Transformerブロックに空間と時間のアテンション計算が別々に含まれる[16, 32, 33]。これにより空間と時間の両方の混合が可能になり、完全なクロスアテンションよりも効率的です。ただし、ネットワークの実効的な深さが2倍になります。
\ アテンションメカニズムを設計するにあたり、多くの時系列において、時間関係は空間関係よりも重要または予測的であるという直感に従います。証拠として、空間方向の関係を完全に無視するモデル(PatchTST[14]やTimesFM[19]など)でも、多変量データセットで競争力のあるパフォーマンスを達成できることを観察しています。ただし、他の研究(例:Moirai[15])では、アブレーション実験を通じて、空間方向の関係を含めることに明確な利点があることが示されています。
\ そこで私たちは、「比例因数分解空間時間アテンション」と呼ぶ因数分解アテンションの新しい変種を提案します。空間方向と時間方向のアテンションブロックを交互に混合して使用します。設定可能なハイパーパラメータとして、時間方向と空間方向のブロックの比率を変更でき、各種類のアテンションに多かれ少なかれ計算予算を割り当てることができます。基本モデルでは、時間方向ブロック2つに対して空間方向アテンションブロック1つの構成を選択しました。
\ 時間方向アテンションブロックでは、時間依存特徴を自己回帰的にモデル化するために、因果マスキングとXPOS[35]を使用した回転位置埋め込み[34]を使用します。対照的に、空間方向ブロックでは、共変量の置換不変性を保持するために完全な双方向アテンションを使用し、関連する変量のみが互いにアテンションを向けるようにブロック対角IDマスクを使用します。このマスキングにより、複数の独立した多変量時系列を同じバッチにパックすることができ、トレーニング効率を向上させ、パディングの量を減らすことができます。
\ 3.4 確率的予測ヘッド
\ 予測アプリケーションに役立つためには、モデルは確率的予測を生成する必要があります。時系列モデルでの一般的な方法は、モデルが確率分布のパラメータを回帰する出力層を使用することです。これにより、モンテカルロサンプリング[7]を使用して予測区間を計算することができます。
\ 出力層の一般的な選択肢は正規分布[7]とStudent-T分布[23, 36]で、外れ値に対する堅牢性を向上させることができます。Moirai[15]は、ガウス分布、Student-T分布、対数正規分布、負の二項分布の出力の重み付き組み合わせを組み込んだ新しい混合モデルを提案することで、より柔軟な残差分布を可能にします。
\ しかし、実世界の時系列は、外れ値、重い裾、極端な歪み、多峰性など、適合が難しい複雑な分布を持つことがよくあります。これらのシナリオに対応するために、さらに柔軟な出力尤度を導入します。そのために、任意の密度関数を近似できるガウス混合モデル(GMM)に基づく方法を採用します([37])。外れ値の存在下でのトレーニングの不安定性を避けるために、Student-T混合モデル(SMM)を使用します。これはGMMの堅牢な一般化[38]であり、重い裾を持つ金融時系列のモデリングに有望であることが以前から示されています[39, 40]。モデルは各時間ステップに対してkのStudent-T分布(kはハイパーパラメータ)と学習された重み付けを予測します。
\ 
\ 推論を実行する際、各タイムスタンプで混合分布からサンプルを抽出し、各サンプルを次の予測のためにデコーダーに戻します。これにより、サンプル数によってのみ制限される任意の分位数で予測区間を生成することができます。より正確な裾のために、サンプリングにより多くの計算を費やすことを選択できます(図2)。
\ 3.5 入力/出力のスケーリング
\ 他の時系列モデルと同様に、モデルが異なるスケールの入力に対してより良く一般化するために、パッチ埋め込みに通す前に入力データにインスタンス正規化を実行します[41]。入力をゼロ平均と単位標準偏差を持つようにスケーリングします。出力予測は元の単位に再スケーリングされます。
\ 3.6 トレーニング目標
\ デコーダーのみのモデルとして、Totoは次のパッチ予測タスクで事前トレーニングされています。モデルの分布出力に関して、次に予測されるパッチの負の対数尤度を最小化します。モデルのトレーニングにはAdamWオプティマイザ[42]を使用します。
\ 3.7 ハイパーパラメータ
\ Totoに使用されるハイパーパラメータは表A.1に詳述されており、総パラメータ数は1億300万です。
\
:::info 著者:
(1) Ben Cohen (ben.cohen@datadoghq.com);
(2) Emaad Khwaja (emaad@datadoghq.com);
(3) Kan Wang (kan.wang@datadoghq.com);
(4) Charles Masson (charles.masson@datadoghq.com);
(5) Elise Rame (elise.rame@datadoghq.com);
(6) Youssef Doubli (youssef.doubli@datadoghq.com);
(7) Othmane Abou-Amal (othmane@datadoghq.com).
:::
:::info この論文は arxivで入手可能 でCC BY 4.0ライセンスの下で公開されています。
:::
\


関連コンテンツ

SPX6900は先月7.44%上昇し、2026年4月16日までに$0.249658に下落すると予測されています

暗号資産トレンド:2025年にソーシャルメディアとAI検索を席巻するトップ5のデジタル資産




