

混合適応手法が言語モデルのファインチューニングをより安価でスマートにする方法
リンク一覧
概要と1. はじめに
-
背景
2.1 Mixture-of-Experts
2.2 アダプター
-
Mixture-of-Adaptations
3.1 ルーティングポリシー
3.2 一貫性正則化
3.3 適応モジュールのマージと3.4 適応モジュールの共有
3.5 ベイジアンニューラルネットワークとモデルアンサンブルとの関連
-
実験
4.1 実験設定
4.2 主要な結果
4.3 アブレーション研究
-
関連研究
-
結論
-
制限事項
-
謝辞と参考文献
付録
A. 少数ショットNLUデータセット B. アブレーション研究 C. NLUタスクの詳細結果 D. ハイパーパラメータ
3 Mixture-of-Adaptations

\
3.1 ルーティングポリシー
THOR(Zuo et al., 2021)のような最近の研究では、ランダムルーティングのような確率的ルーティングポリシーが、以下の利点を持つSwitchルーティング(Fedus et al., 2021)のような古典的なルーティングメカニズムと同様に機能することが示されています。入力例がランダムに異なる専門家にルーティングされるため、各専門家が活性化される機会が均等になり、フレームワークが簡素化されるため、追加の負荷分散は必要ありません。さらに、専門家選択のためのSwitchレイヤーには追加のパラメータがなく、したがって追加の計算もありません。後者は、単一の適応モジュールと同じパラメータとFLOPを維持するためのパラメータ効率の良い微調整の設定において特に重要です。AdaMixの動作を分析するために、セクション3.5で確率的ルーティングとモデル重み平均化をベイジアンニューラルネットワークとモデルアンサンブルに関連付けることを示します。
\ \ 
\ \ このような確率的ルーティングにより、適応モジュールはトレーニング中に異なる変換を学習し、タスクの複数のビューを取得できます。ただし、トレーニング中のランダムルーティングプロトコルにより、推論時にどのモジュールを使用するかという課題も生じます。私たちは、適応モジュールを統合し、単一モジュールと同じ計算コスト(FLOPs、調整可能な適応パラメータ数)を得ることができる以下の2つの技術でこの課題に対処します。
3.2 一貫性正則化
\ 
\ \ \ 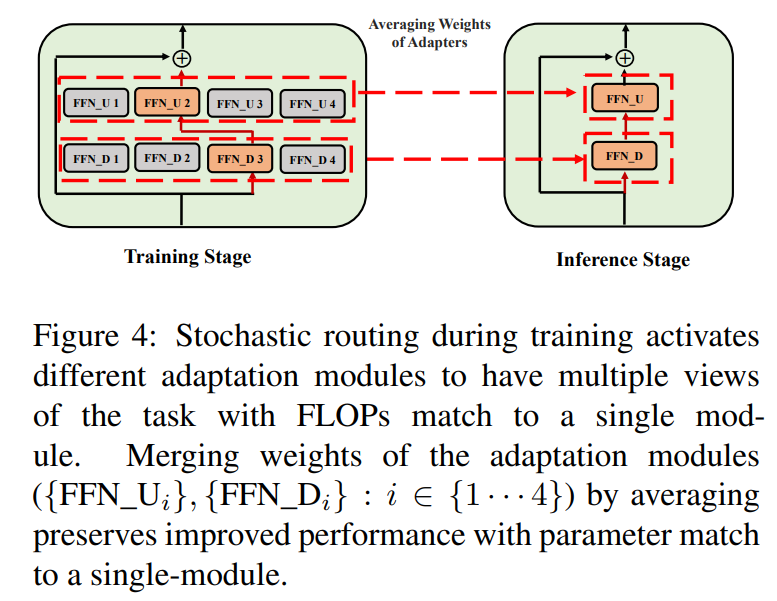
3.3 適応モジュールのマージ
上記の正則化は推論時のランダムモジュール選択の不一致を軽減しますが、複数の適応モジュールをホストするためのサービング費用の増加をもたらします。下流タスク向けの言語モデルの微調整に関する以前の研究では、異なるランダムシードで微調整された異なるモデルの重みを平均化することで、単一の微調整モデルを上回るパフォーマンスが示されています。最近の研究(Wortsman et al., 2022)では、同じ初期化から異なる微調整を行ったモデルが同じエラー盆地に存在することも示されており、堅牢なタスク要約のための重み集約の使用が動機付けられています。私たちは、マルチビュー適応モジュールのパラメータ効率の良いトレーニングに、言語モデル微調整のための以前の技術を採用し拡張しています。
\ \ 
\
3.4 適応モジュールの共有
\ 
3.5 ベイジアンニューラルネットワークとモデルアンサンブルとの関連
\ 
\ \ これには、すべての可能なモデルの重みの平均化が必要ですが、実際には計算が困難です。そのため、ドロップアウトを使用した変分推論法と確率的正則化技術に基づくいくつかの近似方法が開発されています。この研究では、ランダムルーティングの形で別の確率的正則化を活用しています。ここでの目的は、計算が困難な真のモデル事後分布を置き換えることができる、扱いやすい分布族の中で代理分布qθ(w)を見つけることです。理想的な代理は、候補と真の事後分布間のKullback-Leibler(KL)ダイバージェンスを最小化することによって特定されます。
\ \ 
\ \ \ 
\ \ \ 
\ \ \ \
:::info 著者:
(1) Yaqing Wang, パデュー大学 (wang5075@purdue.edu);
(2) Sahaj Agarwal, Microsoft (sahagar@microsoft.com);
(3) Subhabrata Mukherjee, Microsoft Research (submukhe@microsoft.com);
(4) Xiaodong Liu, Microsoft Research (xiaodl@microsoft.com);
(5) Jing Gao, パデュー大学 (jinggao@purdue.edu);
(6) Ahmed Hassan Awadallah, Microsoft Research (hassanam@microsoft.com);
(7) Jianfeng Gao, Microsoft Research (jfgao@microsoft.com).
:::
:::info この論文は arxivで入手可能 で、CC BY 4.0 DEEDライセンスの下で公開されています。
:::
\


関連コンテンツ

「こんなこと作り話にもできない」:メラニア・トランプのエプスタイン否定に観察者たちが言葉を失う

イラン戦争:米国防総省が攻撃について虚偽の説明をしたと兵士らが主張




