

Extraction sémantique en ensemble ouvert : Pipeline Grounded-SAM, CLIP et DINOv2
Table des liens
Abstrait et 1 Introduction
-
Travaux connexes
2.1. Navigation basée sur la vision et le langage
2.2. Compréhension sémantique de scène et segmentation d'instance
2.3. Reconstruction de scène 3D
-
Méthodologie
3.1. Collecte de données
3.2. Informations sémantiques en ensemble ouvert à partir d'images
3.3. Création de la représentation 3D en ensemble ouvert
3.4. Navigation guidée par le langage
-
Expériences
4.1. Évaluation quantitative
4.2. Résultats qualitatifs
-
Conclusion et travaux futurs, Déclaration de divulgation et Références
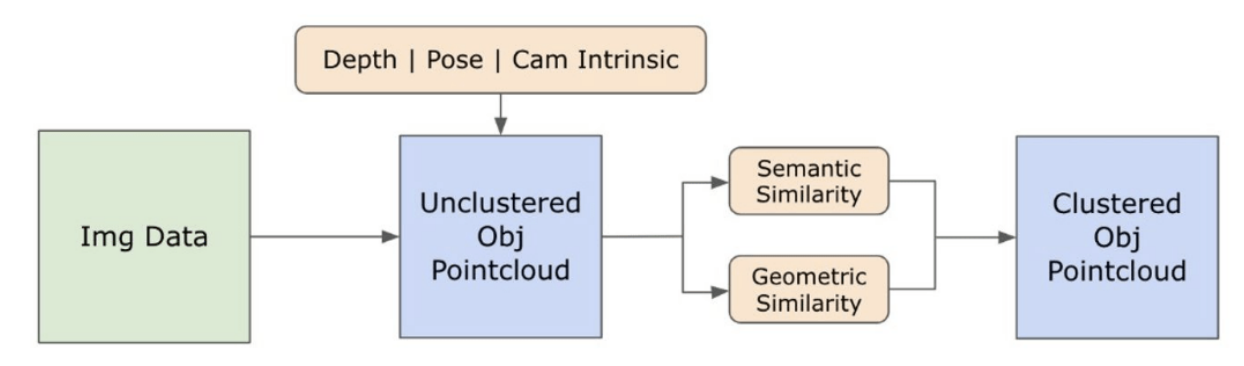
3.2. Informations sémantiques en ensemble ouvert à partir d'images
\ 3.2.1. Détection de masques sémantiques et d'instances en ensemble ouvert
\ Le modèle Segment Anything (SAM) [21] récemment publié a gagné une popularité significative parmi les chercheurs et les praticiens industriels grâce à ses capacités de segmentation de pointe. Cependant, SAM a tendance à produire un nombre excessif de masques de segmentation pour le même objet. Nous adoptons le modèle Grounded-SAM [32] pour notre méthodologie afin de résoudre ce problème. Ce processus implique la génération d'un ensemble de masques en trois étapes, comme illustré dans la Figure 2. Initialement, un ensemble d'étiquettes textuelles est créé à l'aide du modèle Recognizing Anything (RAM) [33]. Ensuite, des boîtes englobantes correspondant à ces étiquettes sont créées à l'aide du modèle Grounding DINO [25]. L'image et les boîtes englobantes sont ensuite introduites dans SAM pour générer des masques de segmentation agnostiques de classe pour les objets visibles dans l'image. Nous fournissons une explication détaillée de cette approche ci-dessous, qui atténue efficacement le problème de sur-segmentation en incorporant des informations sémantiques de RAM et Grounding-DINO.
\ Le modèle RAM [33] traite l'image RGB d'entrée pour produire un étiquetage sémantique de l'objet détecté dans l'image. C'est un modèle fondamental robuste pour l'étiquetage d'images, démontrant une remarquable capacité zero-shot à identifier avec précision diverses catégories communes. La sortie de ce modèle associe chaque image d'entrée à un ensemble d'étiquettes qui décrivent les catégories d'objets dans l'image. Le processus commence par accéder à l'image d'entrée et la convertir dans l'espace couleur RGB, puis la redimensionner pour répondre aux exigences d'entrée du modèle, et enfin la transformer en tenseur, la rendant compatible avec l'analyse par le modèle. Suite à cela, le modèle RAM génère des étiquettes, ou tags, qui décrivent les divers objets ou caractéristiques présents dans l'image. Un processus de filtration est employé pour affiner les étiquettes générées, ce qui implique la suppression des classes indésirables de ces étiquettes. Plus précisément, les tags non pertinents tels que "mur", "sol", "plafond" et "bureau" sont écartés, ainsi que d'autres classes prédéfinies jugées inutiles pour le contexte de l'étude. De plus, cette étape permet l'augmentation de l'ensemble d'étiquettes avec toutes les classes requises non initialement détectées par le modèle RAM. Enfin, toutes les informations pertinentes sont agrégées dans un format structuré. Plus précisément, chaque image est cataloguée dans le dictionnaire img_dict, qui enregistre le chemin de l'image ainsi que l'ensemble des étiquettes générées, assurant ainsi un référentiel accessible de données pour une analyse ultérieure.
\ Suite à l'étiquetage de l'image d'entrée avec les étiquettes générées, le flux de travail progresse en invoquant le modèle Grounding DINO [25]. Ce modèle se spécialise dans l'ancrage de phrases textuelles à des régions spécifiques d'une image, délimitant efficacement les objets cibles avec des boîtes englobantes. Ce processus identifie et localise spatialement les objets dans l'image, posant les bases pour des analyses plus granulaires. Après avoir identifié et localisé les objets via des boîtes englobantes, le modèle Segment Anything (SAM) [21] est employé. La fonction principale du modèle SAM est de générer des masques de segmentation pour les objets à l'intérieur de ces boîtes englobantes. Ce faisant, SAM isole les objets individuels, permettant une analyse plus détaillée et spécifique à l'objet en séparant efficacement les objets de leur arrière-plan et les uns des autres dans l'image.
\ À ce stade, les instances d'objets ont été identifiées, localisées et isolées. Chaque objet est identifié avec divers détails, y compris les coordonnées de la boîte englobante, un terme descriptif pour l'objet, la probabilité ou le score de confiance de l'existence de l'objet exprimé en logits, et le masque de segmentation. De plus, chaque objet est associé à des caractéristiques d'embedding CLIP et DINOv2, dont les détails sont élaborés dans la sous-section suivante.
\ 3.2.2. L'extraction d'embedding sémantique
\ Pour améliorer notre compréhension des aspects sémantiques des instances d'objets qui ont été segmentées et masquées dans nos images, nous employons deux modèles, CLIP [9] et DINOv2 [10], pour dériver les représentations de caractéristiques à partir des images recadrées de chaque objet. Un modèle entraîné exclusivement avec CLIP atteint une compréhension sémantique robuste des images mais ne peut pas discerner la profondeur et les détails complexes au sein de ces images. D'autre part, DINOv2 démontre des performances supérieures dans la perception de la profondeur et excelle dans l'identification des relations nuancées au niveau des pixels à travers les images. En tant que Vision Transformer auto-supervisé, DINOv2 peut extraire des détails de caractéristiques nuancés sans s'appuyer sur des données annotées, ce qui le rend particulièrement efficace pour identifier les relations spatiales et les hiérarchies dans les images. Par exemple, alors que le modèle CLIP pourrait avoir du mal à différencier deux chaises de couleurs différentes, comme rouge et verte, les capacités de DINOv2 permettent de faire clairement de telles distinctions. Pour conclure, ces modèles capturent à la fois les caractéristiques sémantiques et visuelles des objets, qui sont ensuite utilisées pour des comparaisons de similarité dans l'espace 3D.
\ 
\ Un ensemble d'étapes de prétraitement est mis en œuvre pour le traitement des images avec le modèle DINOv2. Celles-ci incluent le redimensionnement, le recadrage central, la conversion de l'image en tenseur, et la normalisation des images recadrées délimitées par les boîtes englobantes. L'image traitée est ensuite introduite dans le modèle DINOv2 avec les étiquettes identifiées par le modèle RAM pour générer les caractéristiques d'embedding DINOv2. D'autre part, lorsqu'on traite avec le modèle CLIP, l'étape de prétraitement implique la transformation de l'image recadrée en un format tenseur compatible avec CLIP, suivie du calcul des caractéristiques d'embedding. Ces embeddings sont critiques car ils encapsulent les attributs visuels et sémantiques des objets, qui sont cruciaux pour une compréhension complète des objets dans la scène. Ces embeddings subissent une normalisation basée sur leur norme L2, qui ajuste le vecteur de caractéristiques à une longueur unitaire standardisée. Cette étape de normalisation permet des comparaisons cohérentes et équitables entre différentes images.
\ Dans la phase d'implémentation de cette étape, nous itérons sur chaque image dans nos données et exécutons les procédures suivantes :
\ (1) L'image est recadrée à la région d'intérêt en utilisant les coordonnées de la boîte englobante fournies par le modèle Grounding DINO, isolant l'objet pour une analyse détaillée.
\ (2) Générer les embeddings DINOv2 et CLIP pour l'image recadrée.
\ (3) Enfin, les embeddings sont stockés avec les masques de la section précédente.
\ Avec ces étapes terminées, nous possédons maintenant des représentations de caractéristiques détaillées pour chaque objet, enrichissant notre ensemble de données pour une analyse et une application ultérieures.
\
:::info Auteurs :
(1) Laksh Nanwani, International Institute of Information Technology, Hyderabad, Inde ; cet auteur a contribué de manière égale à ce travail ;
(2) Kumaraditya Gupta, International Institute of Information Technology, Hyderabad, Inde ;
(3) Aditya Mathur, International Institute of Information Technology, Hyderabad, Inde ; cet auteur a contribué de manière égale à ce travail ;
(4) Swayam Agrawal, International Institute of Information Technology, Hyderabad, Inde ;
(5) A.H. Abdul Hafez, Hasan Kalyoncu University, Sahinbey, Gaziantep, Turquie ;
(6) K. Madhava Krishna, International Institute of Information Technology, Hyderabad, Inde.
:::
:::info Cet article est disponible sur arxiv sous licence CC by-SA 4.0 Deed (Attribution-Partage dans les mêmes conditions 4.0 International).
:::
\
Vous aimerez peut-être aussi

Plus de 50% de la première cohorte de 3MTT ont abandonné – Alex Onyia

Prédiction des prix de Shiba Inu : SHIB peut-il tenir sa position ou la montée en puissance de Remittix, alimentée par son utilité, le dépassera-t-elle en 2026 ?
