

Transformer-Based Anomaly Detection Using Log Sequence Embeddings
Table of links
Abstract
1 Introduction
2 Background and Related Work
2.1 Different Formulations of the Log-based Anomaly Detection Task
2.2 Supervised v.s. Unsupervised
2.3 Information within Log Data
2.4 Fix-Window Grouping
2.5 Related Works
3 A Configurable Transformer-based Anomaly Detection Approach
3.1 Problem Formulation
3.2 Log Parsing and Log Embedding
3.3 Positional & Temporal Encoding
3.4 Model Structure
3.5 Supervised Binary Classification
4 Experimental Setup
4.1 Datasets
4.2 Evaluation Metrics
4.3 Generating Log Sequences of Varying Lengths
4.4 Implementation Details and Experimental Environment
5 Experimental Results
5.1 RQ1: How does our proposed anomaly detection model perform compared to the baselines?
5.2 RQ2: How much does the sequential and temporal information within log sequences affect anomaly detection?
5.3 RQ3: How much do the different types of information individually contribute to anomaly detection?
6 Discussion
7 Threats to validity
8 Conclusions and References
\
3 A Configurable Transformer-based Anomaly Detection Approach
In this study, we introduce a novel transformer-based method for anomaly detection. The model takes log sequences as inputs to detect anomalies. The model employs a pretrained BERT model to embed log templates, enabling the representation of semantic information within log messages. These embeddings, combined with positional or temporal encoding, are subsequently inputted into the transformer model. The combined information is utilized in the subsequent generation of log sequence-level representations, facilitating the anomaly detection process. We design our model to be flexible: The input features are configurable so that we can use or conduct experiments with different feature combinations of the log data. Additionally, the model is designed and trained to handle input log sequences of varying lengths. In this section, we introduce our problem formulation and the detailed design of our method.
\ 3.1 Problem Formulation
We follow the previous works [1] to formulate the task as a binary classification task, in which we train our proposed model to classify log sequences into anomalies and normal ones in a supervised way. For the samples used in the training and evaluation of the model, we utilize a flexible grouping approach to generate log sequences of varying lengths. The details are introduced in Section 4
\ 3.2 Log Parsing and Log Embedding
In our work, we transform log events into numerical vectors by encoding log templates with a pre-trained language model. To obtain the log templates, we adopt the Drain parser [24], which is widely used and has good parsing performance on most of the public datasets [4]. We use a pre-trained sentence-bert model [25] (i.e., all-MiniLML6-v2 [26]) to embed the log templates generated by the log parsing process. The pre-trained model is trained with a contrastive learning objective and achieves state-ofthe-art performance on various NLP tasks. We utilize this pre-trained model to create a representation that captures semantic information of log messages and illustrates the similarity between log templates for the downstream anomaly detection model. The output dimension of the model is 384.
\ 3.3 Positional & Temporal Encoding
The original transformer model [27] adopts a positional encoding to enable the model to make use of the order of the input sequence. As the model contains no recurrence and no convolution, the models will be agnostic to the log sequence without the positional encoding. While some studies suggest that transformer models without explicit positional encoding remain competitive with standard models when dealing with sequential data [28, 29], it is important to note that any permutation of the input sequence will produce the same internal state of the model. As sequential information or temporal information may be important indicators for anomalies within log sequences, previous works that are based on transformer models utilize the standard positional encoding to inject the order of log events or templates in the sequence [11, 12, 21], aiming to detect anomalies associated with the wrong execution order. However, we noticed that in a common-used replication implementation of a transformer-based method [5], the positional encoding was, in fact, omitted. To the best of our knowledge, no existing work has encoded the temporal information based on the timestamps of logs for their anomaly detection method. The effectiveness of utilizing sequential or temporal information in the anomaly detection task is unclear.
\ In our proposed method, we attempt to incorporate sequential and temporal encoding into the transformer model and explore the importance of sequential and temporal information for anomaly detection. Specifically, our proposed method has different variants utilizing the following sequential or temporal encoding techniques. The encoding is then added to the log representation, which serves as the input to the transformer structure.
\ 
3.3.1 Relative Time Elapse Encoding (RTEE)
We propose this temporal encoding method, RTEE, which simply substitutes the position index in positional encoding with the timing of each log event. We first calculate the time elapse according to the timestamps of log events in the log sequence. Instead of using the log event sequence index as the position to sinusoidal and cosinusoidal equations, we use the relative time elapse to the first log event in the log sequence to substitute the position index. Table 1 shows an example of time intervals in a log sequence. In the example, we have a log sequence containing 7 events with a time span of 7 seconds. The elapsed time from the first event to each event in the sequence is utilized to calculate the time encoding for the corresponding events. Similar to positional encoding, the encoding is calculated with the above-mentioned equations 1, and the encoding will not update during the training process.
\ 
3.4 Model Structure
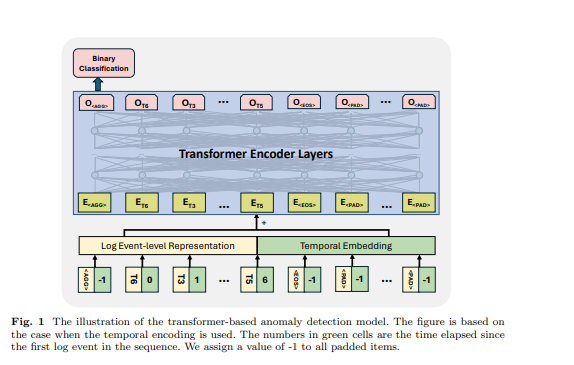
The transformer is a neural network architecture that relies on the self-attention mechanism to capture the relationship between input elements in a sequence. The transformer-based models and frameworks have been used in the anomaly detection task by many previous works [6, 11, 12, 21]. Inspired by the previous works, we use a transformer encoder-based model for anomaly detection. We design our approach to accept log sequences of varying lengths and generate sequence-level representations. To achieve this, we have employed some specific tokens in the input log sequence for the model to generate sequence representation and identify the padded tokens and the end of the log sequence, drawing inspiration from the design of the BERT model [31]. In the input log sequence, we used the following tokens: is placed at the start of each sequence to allow the model to generate aggregated information for the entire sequence, is added at the end of the sequence to signify its completion, is used to mark the masked tokens under the self-supervised training paradigm, and is used for padded tokens. The embeddings for these special tokens are generated randomly based on the dimension of the log representation used. An example is shown in Figure 1, the time elapsed for , and are set to -1. The log event-level representation and positional or temporal embedding are summed as the input feature of the transformer structure.
\ 3.5 Supervised Binary Classification Under this training objective, we utilize the output of the first token of the transformer model while ignoring the outputs of the other tokens. This output of the first token is designed to aggregate the information of the whole input log sequence, similar to the token of the BERT model, which provides an aggregated representation of the token sequence. Therefore, we consider the output of this token as a sequence-level representation. We train the model with a binary classification objective (i.e., Binary Cross Entropy Loss) with this representation.
\ 
:::info Authors:
- Xingfang Wu
- Heng Li
- Foutse Khomh
:::
:::info This paper is available on arxiv under CC by 4.0 Deed (Attribution 4.0 International) license.
:::
\
You May Also Like

The Top 10 Altcoins Most Purchased by Investors in 2025 Have Been Revealed! There’s a Trump Detail Too!

The high premium of silver funds has attracted attention; Guotou Silver LOF will be suspended from trading from the opening of the market on December 26 until 10:30 a.m. on the same day.
